

TL;DR
LLMs like ChatGPT, Gemini, and Claude now ship with memory — but each traps it inside their own silo OpenAI Anthropic VentureBeat The Verge. This design locks users in, fragments the ecosystem, and prevents AI from compounding intelligence across systems.
True intelligence requires adaptive memory: systems that can prioritize, weight, and resurface information based on relevance over time, not just store or delete it.
What’s missing is a protocol for interoperable memory, like OAuth for AI context. Emerging standards like MCP and Google A2A show the way for tool and agent interoperability, but none yet give users portable, adaptive memory.
Startups like Plurality, Mem0, Epicenter, and SurrealDB are building toward this future. The stakes are clear: either we get trapped in walled gardens of brilliant amnesiacs, or we create an open layer that lets AI grow with us.
AI Without Memory: The Missing Protocol for Interoperability
The most serious limitation of today’s AI systems is not their reasoning power, but their amnesia.
Spend months working with ChatGPT, Gemini, or Claude, and you build context. The system begins to mirror your style, anticipate your needs, and give the impression of continuity. Switch to another provider, and everything disappears. You start again from zero.
Providers designed it this way.
Providers Build Walled Gardens
Each large model locks memory, preferences, and history inside its own ecosystem. OpenAI introduced memory for ChatGPT on February 13, 2024, and upgraded it on September 5, 2024 so that memory is available to Free, Plus, Team, and Enterprise users, with “saved memories” and referenceable chat history across conversations 1.
Anthropic added memory to Claude on September 11–12, 2025, rolling out the feature to Team and Enterprise users. Claude now remembers project context, preferences, and team processes, and offers an “incognito chat” option that keeps conversations out of memory 23.
Google introduced personalized memory and past-chat referencing features for Gemini on August 13, 2025, including “Temporary Chat” modes so users can choose not to persist conversations permanently 4.
These memory systems live inside each vendor’s platform. None of them yet provide standardized portability of memory or context across providers. Vendors profit by making switching painful. The deeper you go with one provider, the harder it becomes to leave.
This design may benefit providers, but it damages users and the broader ecosystem.
Users waste time repeating themselves and re-establishing context, which limits the depth of collaboration. The ecosystem suffers fragmentation, as each model evolves in isolation rather than building on shared intelligence.
Every general-purpose technology that scaled—whether the internet, email, or telephony—did so only after interoperability standards dismantled these kinds of barriers. AI has not reached that stage.
Memory, Decay, and Relevance
Intelligence depends on how effectively a system prioritizes information. Humans do not treat all memories equally. We assign weight to experiences based on our needs, predictions, and goals.
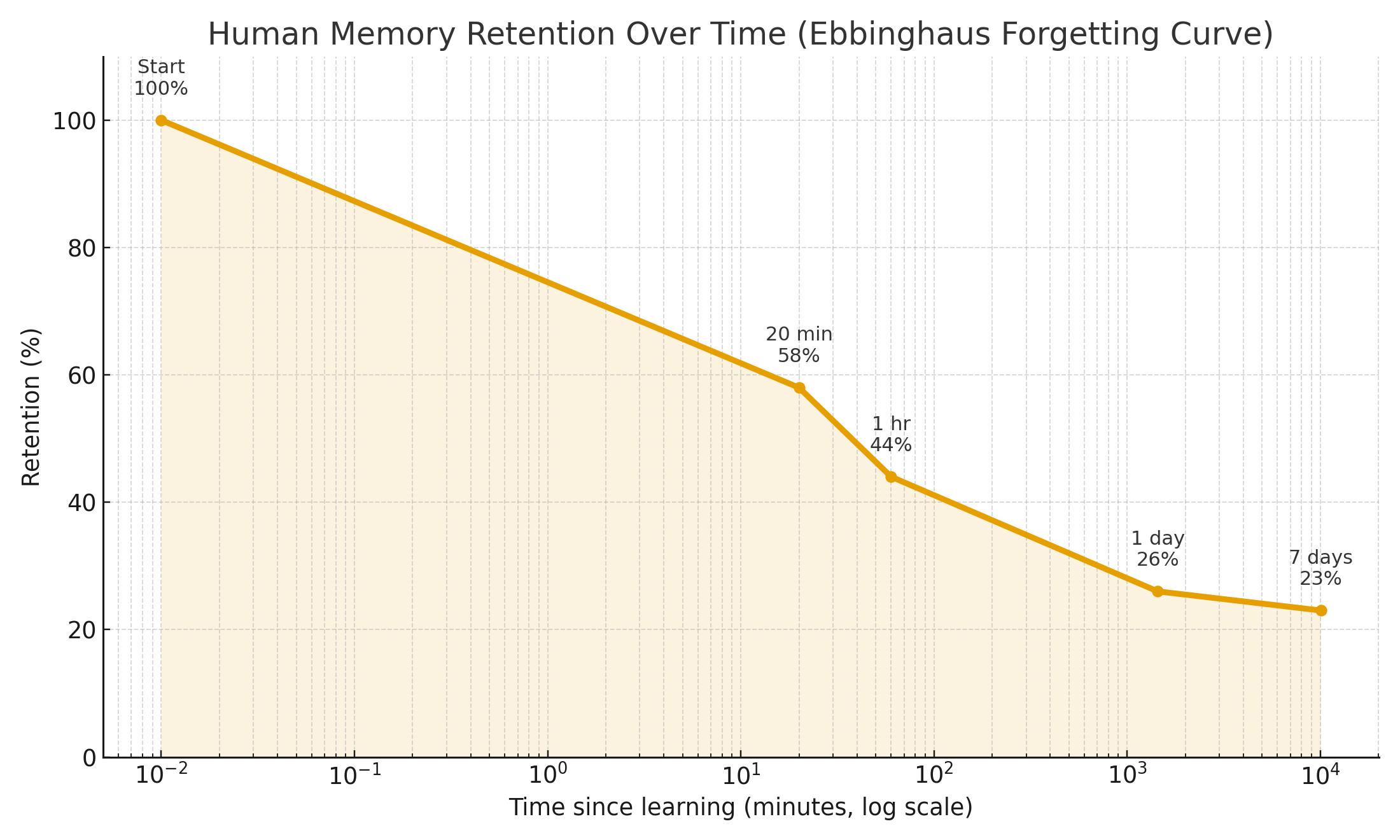
This classic curve, first described by Hermann Ebbinghaus in 1885, shows how human memory decays over time without reinforcement. Retention drops steeply within the first hour, then declines more gradually across days and weeks. Learn more on Wikipedia: Forgetting curve: https://en.wikipedia.org/wiki/Forgetting_curve
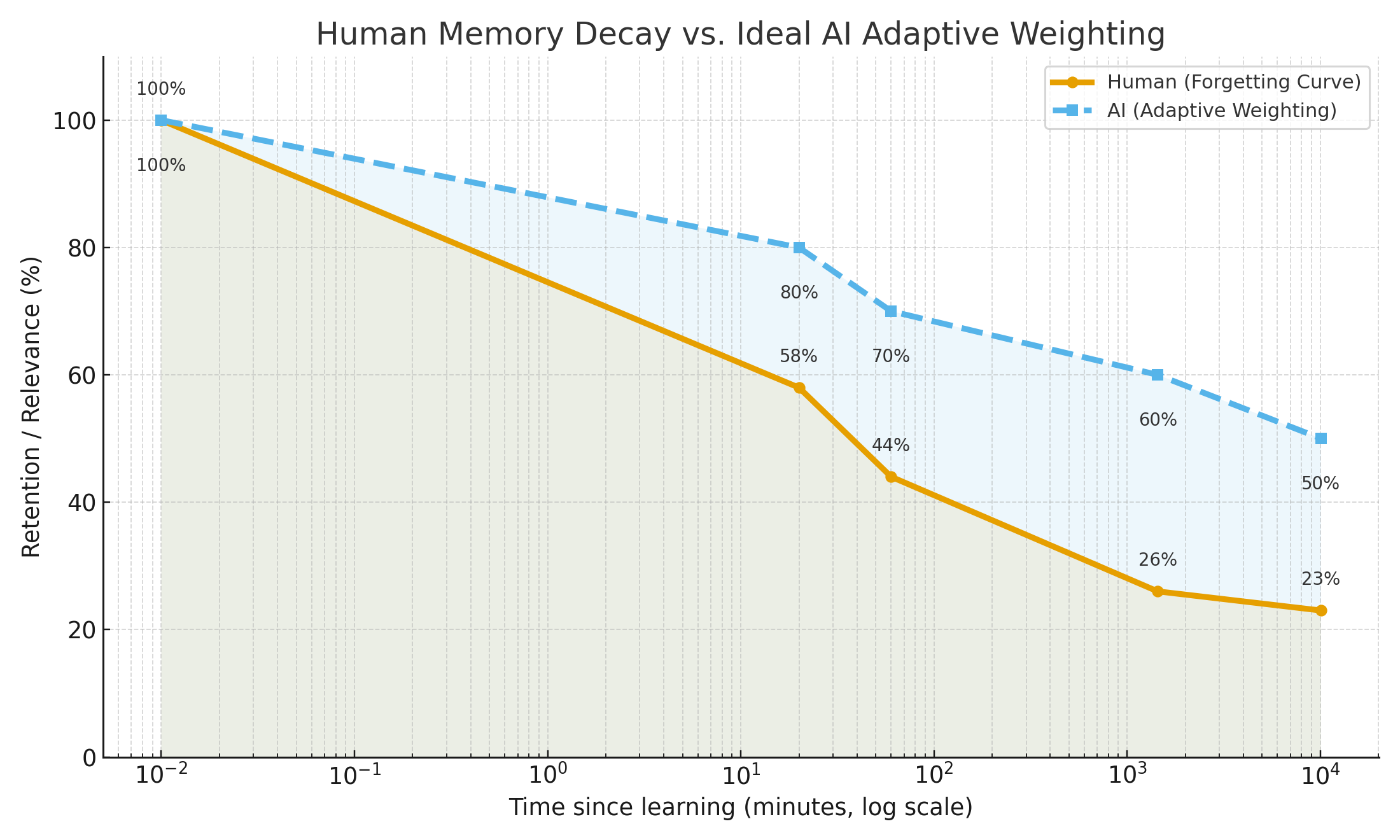
Human Memory Decay vs. Ideal AI Adaptive Weighting
Comparing human memory decay with an ideal AI adaptive weighting system. While humans lose detail quickly, an AI could maintain higher relevance over time by dynamically reweighting memory rather than discarding it.
What feels critical today may fade in priority as our lives evolve. What once seemed irrelevant may gain new importance when circumstances shift.
AI must operate in the same way. Memory decay is not about erasing the past, it is about recalibrating relevance over time. A robust system should continually evaluate which information deserves focus, which context should recede, and which insights should resurface when conditions demand it.
This kind of adaptive memory would make AI more useful and more human-like. Instead of clinging to static snapshots, systems would adjust to the user’s growth, preferences, and desired outcomes. Today’s LLMs lack this capability. They either hold too little context or attempt to preserve too much, without any mechanism to prioritize by time, situation, or value.
Without dynamic memory weighting, AI remains brittle. It cannot mature alongside the people who rely on it.
Collective Memory and the Enterprise
This problem scales beyond individuals. Enterprises also depend on memory, what we call collective memory.
Every organization relies on three layers of memory:
Personal Memory: the knowledge, preferences, and context of individuals,
Team Memory: the shared workflows, projects, and communications that drive collaboration,
Enterprise Memory: the strategic knowledge, brand, culture, regulatory frameworks, and operational standards that ensure continuity.
Overlaying these layers are the non-negotiables: regulation, legal, corporate standards, and compliance. They define how companies operate, safeguard trust, and protect against risk.
When AI systems keep memory siloed inside vendors, enterprises lose continuity across these layers. The risks are not theoretical:
Fragmented brand voice across teams and regions,
Loss of institutional knowledge when employees leave,
Compliance failures when standards are applied inconsistently,
Strategic drift when critical history is trapped inside disconnected tools.
Enterprises that adopt interoperable, adaptive memory will preserve collective intelligence. They will maintain a consistent brand, protect institutional knowledge, and strengthen resilience in the face of change. They will also unlock new levels of creativity and execution because their memory will scale across individuals, teams, and the enterprise as a whole.
This is more than efficiency. It is about control, trust, and long-term positioning. The companies that set enterprise memory as a future operational standard will define the competitive edge in the AI era.
Building a Protocol for Interoperable Memory
AI needs a protocol for memory. Not another silo, not another proprietary lock-in, but a shared foundation.
Early standards have already emerged for context and agent interoperability. Anthropic introduced the Model Context Protocol (MCP) in November 2024, which provides a standard way for AI systems to securely connect with external tools and data sources 5. Google announced its Agent-to-Agent (A2A) protocol in April 2025, explicitly positioned as complementary to MCP 6.
But these standards do not solve the core problem of user-controlled memory. They focus on how AI connects to tools, not on how users carry context across providers.
Several startups are now pushing directly into this gap:
Plurality Network’s Open Context Layer (OCL) creates a user-controlled, interoperable layer for carrying preferences, history, and identity across AI systems 7.
Mem0, used by more than 50,000 developers, offers an open-source “universal memory layer” that works with OpenAI, Anthropic, Google, and others. It recently introduced OpenMemory MCP, a local-first memory system compatible with MCP clients 8.
Epicenter (YC) brands itself as “ChatGPT’s memory in an open, portable format,” aiming to let users move chat history into other apps and act as an SSO for AI applications 9.
SurrealDB’s SurrealMCP provides persistent, permission-aware memory over live structured data, again built on MCP for interoperability 10.
The idea is clear: users should carry their contextual history across systems in a secure, opt-in, and portable way. That history should behave like a living memory: it should adapt, expire, or resurface based on relevance and time.
Imagine OAuth for AI memory, but built with temporal intelligence. Users could grant a system access to the parts of their history that matter now, revoke it when they choose, and rely on adaptive weighting to ensure their context reflects current needs rather than static archives.
Such a protocol would:
Give users ownership and control over their own context.
Lower switching costs and encourage experimentation across providers.
Push vendors to compete on value rather than lock-in.
Enable AI memory to act more like human memory—dynamic, adaptive, and tied to growth.
The Stakes
If providers continue to trap memory in silos, AI will fracture. Each vendor will own a fragment of your history, but none will capture your evolving story. Users will endure inefficiency, providers will consolidate control, and the ecosystem will stagnate.
If we build interoperable, adaptive memory, AI will cross a threshold. It will move from static tools to evolving systems of intelligence that grow with their users. This shift would unlock a wave of productivity and creativity while restoring control to the people who rely on these systems.
Every transformative technology achieved scale by moving from proprietary silos to shared standards. AI will follow the same path.
The choice is clear: either we accept a future defined by lock-in and amnesia, or we demand interoperability, adaptive memory, and context that matures with us.
Interoperable memory is not optional. It is the missing protocol for the next era of AI.
If you know anyone actively working on the problem of interoperable, adaptive AI memory, personal or enterprise, I’d love to talk with them. Please share or reach out.
Footnotes
OpenAI – Memory and new controls for ChatGPT (Feb 13 & Sept 5, 2024) openai.com ↩
Anthropic – Memory for Claude Teams/Enterprise (Sept 12, 2025) anthropic.com ↩
VentureBeat – Anthropic adds memory to Claude (Sept 12, 2025) venturebeat.com ↩
The Verge – Gemini adds memory & personalization (Aug 13, 2025) theverge.com ↩
Anthropic – Introducing the Model Context Protocol (MCP) (Nov 2024) anthropic.com ↩
Google – Introducing the A2A Protocol (Apr 2025) ai.google ↩
Plurality Network – Open Context Layer overview (2025) plurality.network ↩
Mem0 – Docs and ArXiv paper on scalable memory (Apr 2025) arxiv.org | mem0.ai ↩
Epicenter – Y Combinator batch profile (2025) ycombinator.com ↩
SurrealDB – SurrealMCP announcement (2025) surrealdb.com ↩